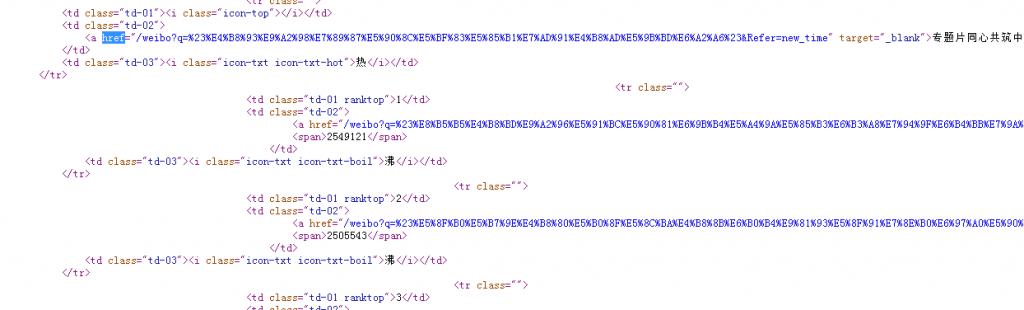
一,背景 最近自己准备写一个热门排行榜的功能,自己百度一下Node js 能够解析html的库,自己找到cheerio,这个库发现非常适合自己,因为他的用法跟jquery 类似。于是我拿微博热门搜索来练手,熟悉cheerio库,顺便用一个node js 网络库got 二,逻辑 通过网页源代码,可以分析每个tr下面td class=td-02 下面a标签就是我们要找的元素,那么通过jquery 语法写法 $("tbody>tr>td.td-02>a"),逻辑就这么简单。 三,代码 代码是不是非常简单,await 只是…