背景 几个服务器项目用node js,自己开发直接用node xx.js就可以了,但在linux 服务器部署的时候,就必须用nohup ,但如果多个项目就会导致分不了,除非xx.js每个项目不一样,这个时候查看 /proc/pid/cwd 看运行的目录才能知道具体的项目,这样子会导致重启项目很麻烦 解决方案 forever 启动运行 采用pm 管理node项目 采用宝塔的node项目管理 宝塔的node项目管理 直接用宝塔web操起来非常方便,启动、停止、重启非常方便,同时可以设置各种web设置 研究一下宝塔的no…

问题 今天发现node js创建key时候会出现 unsupported hive 错误,这样子就导致程序异常!!! 我发现这个必然会出现这个错误。 解决过程 重现 发现版本 5.1.1 一定出现 跟踪JS到swf文件 分析swf代码,发现返回错误地方 加msgbox 提示会发现循环时候有一处undefined 判断不准,没有过滤掉,导致进入代码逻辑,这个时候应该循环完成 测试代码 async function test(){ await regedit.createKey(['HKCU\\SOFTWAR…
背景 公司的同事自己用socket io实现websocket服务,我用node js websocket去连接发现连接不上,于是我就找我同事。我同事说:必须要用socket io client连接才可以。我觉得很奇怪,一个weocket框架怎么还不能满足普通的实现,我说你是不是代码写错了,后面发现是我理解错了,我同事也理解错了,我们当初定义协议走websocket 通信,协议就直接走json 或者其他自定义协议即可。 自己花了半天时间看帮助文档和代码开发 分析过程 直接分析源代码调试 看官方的帮助文档,全部看完 …

一、前提 我以前只认为node js 只能单线程,我自己用了一段时间electron 桌面开发,如果遇到CPU密集型业务怎么做呢?我不可能只靠一个CPU来搞业务啊,这个限制不是太大了? 二、解决方法 1:多进程 child_process 等模块创建多进程 这种打补丁方法不是很好,涉及进程通信,写代码效率不高,很容易出现bug。开发者很可能出现变量无法访问的问题,因为多个进程,变量没有共享。不过业务写很分开,也问题不大,多进程资源比较大。 2:多线程 worker_threads 真正用的是多线程,我自己写代码测试…
一、背景 我之前写一个工具用来客户端加载网页,同时可以注入js,增加功能,类似chrome 浏览器扩展逻辑,但由于网页总是新建一个窗口,我虽然用JS 注入,修改了所有 a 标签的 。但对于动态的无能为力,除非定时器不停遍历,但性能不好,于是就想从electron入手。 二、过程 自己网络查找一些有关的信息,找到一个new-window 事件,这个事件可以捕获新建窗口逻辑。
一、背景 自己用node request 请求 http 发现请求无法正确应答,我用fidder抓包没有抓对应数据包,因为默认node 不会走 windows 默认代理。 二、解决过程 在request 构建增加参数 proxy: 'http://127.0.0.1:8888' 这个设置代理到fidder里面去,如果非HTTPS 可以直接用wireshark来抓包。 三、补充 如果是第三方程序,如果不会默认走代理,可以用proxifier, 这个软件出来很多年,自己可以百度下载,官方可以试用30天。 proxifi…
一, 背景 自己压缩android 截图数据压缩然后网络传递给我node程序,然后发现node 无法解压。 二,排错过程 打印java 压缩的二进制数据数组,打印node收到 buffer,发送java数组函数负数,而node 得到没有负数 三,思考 看到这个2边数据不一样,我就想起来是什么导致。java byte 是 -128~127,node byte是 0~255. 这样子导致数据对不上,我要说一点二进制数据是一样的。这个只是node 读同样的二进制,解析数据0~255范围[byte],java虚拟机解析~1…
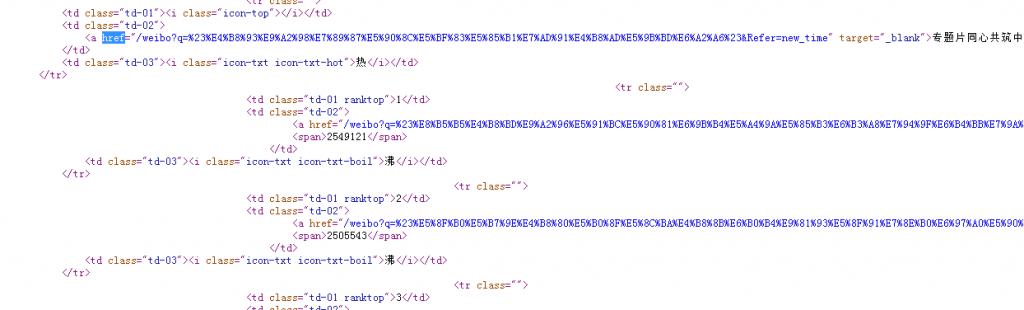
一,背景 最近自己准备写一个热门排行榜的功能,自己百度一下Node js 能够解析html的库,自己找到cheerio,这个库发现非常适合自己,因为他的用法跟jquery 类似。于是我拿微博热门搜索来练手,熟悉cheerio库,顺便用一个node js 网络库got 二,逻辑 通过网页源代码,可以分析每个tr下面td class=td-02 下面a标签就是我们要找的元素,那么通过jquery 语法写法 $("tbody>tr>td.td-02>a"),逻辑就这么简单。 三,代码 代码是不是非常简单,await 只是…
一,说明 electron 不像浏览器会带下载管理,electron 页面调用下载的话,无法感知下载进度,我这里偷懒,直接丢给默认浏览器下载。 二,代码 one_plugin:electron的 windows win-download:触发下载事件 item.cancel():取消electron默认下载逻辑 shell.openExternal:调用默认程序(浏览器)打开url webContents.loadFile:加载自己定义下载界面【因为点击文件下载,会弹出新的窗口,默认是空白的,为了体验好一点,我增加…
一,背景 node js 一般打印日志使用console.log ,如果现有项目希望增加打印日志,那么我们可以重载打印日志函数,我们直接用现有的功能模块 log-timestamp 二,使用 require('log-timestamp'); 导入即可,默认时间戳是用的国际时间,你可以传入你要写的时间戳。 三,原理 重载函数 类似console.log = function(...){ console.old_log(...)}