一、背景 自己因为有一个答题插件逻辑,需要从数据库随机选择一定数目的题目,这个业务已经被同事实现,但我觉得他实现不对或者不够好,于是思考这个问题。他用rand() 产生一个随机数,然后大于这个随机数 加上limit 得到 题库。 二、问题 题库是连续的,用户体验不好 随机概率增大,如果用这个思路写抽奖那么绝对是不对的。 三、解决思路 假设我们选择uid 用户的ID 是整数,主键。。 select * from xxx where uid >= (rand(max(uid) - min(uid) ) + min(ui…

一、背景 自己用node request 请求 http 发现请求无法正确应答,我用fidder抓包没有抓对应数据包,因为默认node 不会走 windows 默认代理。 二、解决过程 在request 构建增加参数 proxy: 'http://127.0.0.1:8888' 这个设置代理到fidder里面去,如果非HTTPS 可以直接用wireshark来抓包。 三、补充 如果是第三方程序,如果不会默认走代理,可以用proxifier, 这个软件出来很多年,自己可以百度下载,官方可以试用30天。 proxifi…
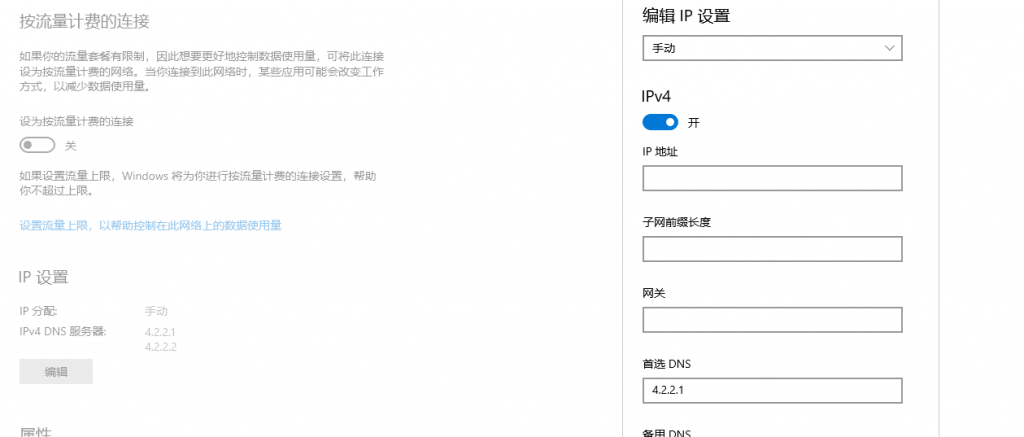
一,问题 edge 虽然可以同步登录,但大多数会出现登录出现问题,我以前都是通过梯子登录,最近发现一个简单方法解决了,自己记录一下。 二,解决 通过填写微软的dns就可以加快登录过程。4.2.2.1 4.2.2.2 这个地址 登录后可以改回自己默认DNS,只是临时切换一下,而可以用网上快速切换DNS的工具,进行快速切换。