一,背景 因为最近项目需要迁移数据库,于是我问了一下后台开发导入数据要多久?结果他说要一个小时,我觉得时间太长了,于是我搜索了一下有关快速插入sql的知识,从而用Node js 写这个小工具,方便快速导入sql。 二,原理 因为我们导出Sql数据是一行一条插入语句,执行sql时候按照每行执行一次,这样子导致写入特别多,大量消耗在网络传输中,于是我们只要把多行插入语句整合一条语句,但这里要知道mysql的一条sql最大长度是1M,所以我合并成一条时候需要注意长度,我用Node js写的工具已经处理这个问题。 三,代码…

一,背景 项目从windows部署到centos,在客户端获取数据出现中文乱码,自己百度半天,各种编码设置也没有解决问题。 二,排查 根据上下文推测,应该跟系统的编码有问题,因为windows 默认编码gdk,然后centos默认编码是utf-8。所以猜测代码里面涉及系统默认编码问题,于是猜测 String getbytes(),如果改成getbytes("utf-8")就没有乱码了。 三,总结 乱码问题,基本都是服务器和客户端编码对不上导致的问题
背景 新手使用electron 会遇遇到自己的html页面加载的Js无法使用node js功能,Preload加载干什么,上下文隔离的问题,这个对于我使用electron确实造成困扰。 关键词 nodeIntegration preload contextIsolation 详解 nodeIntegration 控制渲染进程加载页面是否能够调用node js功能,高版本默认关闭,意思就是加载的html是无法使用node js代码,如果你想用就必须设置 nodeIntegration 为 true。 preload …
背景 今天自己给快速打开增加自动启动,但发现开机启动后 无法正常运行。 排查 通过开发者模式发现路径到C盘系统的目录,我原来用的process.cwd(),返回进程的当前工作目录。后面我换成process.execPath 然后通过path 模块获取文件夹路径,这样子获取一定是安装目录执行的exe。同时不要__dirname 这个代表源码目录,因为打包了,所以目录对不上。
背景 这个之前上传过,但后来发现有bug,导致可能出现不能多开,后面自己修复同时借鉴微软的handle工具【逆向分析】,win8以后【包含win8】,采用新的API,可以减少内存分配,防止内存不够用,导致内部能多开的情况【出现概率还是非常低的】。 原理 这个之前写过,由于自己博客的数据库,被自己不小心删除,导致文章消失了,通过系统API 【微软没有暴露出来】,遍历所有句柄就可以拿到对应的句柄,然后复制句柄,调用关闭即可。【window 核心编程有讲复制API的知识】 代码: https://github.com/x…

一,背景 这个很久之前就想开发的小工具,自己陆陆续续开发一段时间,方便快速打开自己常打开的url.为了练手前端,开始用纯原始的js 开发界面,你会在设置界面发现一个丑陋的菜单,这个就是原生js代码弄的,没有用到前端ui控件,后面接触jquery,amazeui,于是导入进来,现在算是前端基本可以快速开发了。话说对于习惯wpf 和 windows 界面开发,用html开发界面确实不太习惯, 说明 软件快速通过关键词或者关键词的缩写打开对应的网址,因为自己常常会开一些web,进行访问。 这个软件有点借鉴utools,这…
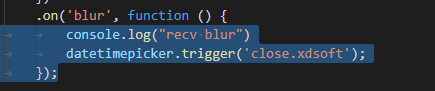
一,背景 自己找了一个datetimepicker, 算是比较流行,但自己测试在IE8没法赋值。他的官网是https://xdsoft.net/jqplugins/datetimepicker/。 二,排查 我从源代码入手,在不同的事件加入日志,最终找到IE8出现代码的地方。 在2573 地方 这里我改成blur,源码对应的blur.xdsoft,第一次看这种写法,自己才最近开始写前端代码,对jquery不是很属性。ie8 选择事件或者点击其他的就会触发blur事件,IE8以上就不会,于是我直接写屏蔽代码。 三,解…