背景
之前自己写过栈的一些东西,但感觉还是写的不好,有一天我在知乎看到一篇文章,写的非常好,所以直接保存自己的博客里面
文章内容
created: 2023-12-10T14:46:55 (UTC +08:00)
tags: []
source: https://www.zhihu.com/collection/741134642
author: DBinary编程等 2 个话题下的优秀答主
(6 封私信 / 5 条消息) 我的收藏 - 收藏夹 - 知乎
Excerpt
知乎,中文互联网高质量的问答社区和创作者聚集的原创内容平台,于 2011 年 1 月正式上线,以「让人们更好的分享知识、经验和见解,找到自己的解答」为品牌使命。知乎凭借认真、专业、友善的社区氛围、独特的产品机制以及结构化和易获得的优质内容,聚集了中文互联网科技、商业、影视、时尚、文化等领域最具创造力的人群,已成为综合性、全品类、在诸多领域具有关键影响力的知识分享社区和创作者聚集的原创内容平台,建立起了以社区驱动的内容变现商业模式。
计算机的出现是为了解决数学计算问题的。因此,我认为纠结菜单名怎么叫的实在没什么意义,最终都要回到“这么做为了解决什么问题”来,为此,我们回到程序媛祖师奶---ada,时至今日,不仅有ada命名的编程语言,还有知名逆向工具IDA也是用了Ada的肖像

最早的程序,是一个计算伯努利数的程序,ada编写了其图表,这个程序运行于巴贝奇的“分析机”中,从仓库中取得数据,然后运算,最后将结果放回仓库中
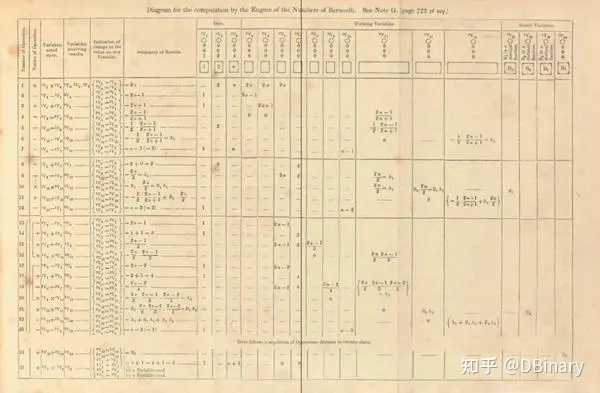
可见,这个“栈”的思想在最早的程序中就有体现了,为了更好的阐述这个过程,我们模仿这个过程试着来计算一个简单的算式,比如一个表达式:
1+2+3
当然,按正常的思路我们先计算
1+2\=3
然后再计算
3+3\=6
上面的表达式分析没什么问题,但是,当我们碰到
1+2∗3
这个表达式的时候,上面的的做法就出问题了,因为乘法的优先级比加法高,因此,当我们看到2的时候,并不能与1进行相加,而是要继续分析后续的表达式
2∗3\=6
只有后面的算完了,前面的才能继续算,因此:
1这个数字,我们必须要先将它放在某个位置存起来,等到后面的操作做完了,再将它取出来用
上面的表达式不够明显,因此,然我们找一个比较长的表达式出来,比如
1+(2−(3+(4−5∗6)))
首先,计算机和我们人类一样,从左往右看,但是当它看到1,2,3,4,5时,都发现这些数字并不能直接计算,因为后面有括号和乘法运算符,这些运算符的优先级都要比加减法高,因此,它需要将这些数字存起来,我们将存放它的地方叫stack,那么就有
stack: 1,2,3,4,5,6
当我们扫描到6的时候,我们发现,后面是右括号了,可以进行计算了,因此,我们从stack中取出5和6进行计算,按照ada计算的思想,得到
5∗6\=30
然后我们将30放回stack中,于是就有了
stack: 1,2,3,4,30
等价的表达式为:
1+(2−(3+(4−30)))
然后我们继续看,发现4-30也可以算了,因此,我们再将4与30从stack中取出来进行计算,算完-26再放回stack中
stack: 1,2,3,−26
等价的表达式为:
1+(2−(3−26))
然后我们继续算下去:
stack: 1,2,−23
1+(2+23)
stack: 1,25
1+25
stack: 26
当stack中只剩下一个26的时候,这个表达式就算计算完成了,在这个过程中我们发现,数据的存储是一个"先进后出""逐步递减"的过程,因此,这种stack的数据管理模式在表达式的运算中实在"太好用"了,因此,这是一个非常实用且记为常用的数据管理思想,应该为其设计专门的硬件让这个过程计算的更快。因此,为了让计算器更好的解决“表达式运算”,栈就这么来了
时至今日,绝大多数的高级语言不论如何发展,AST树如何分析构建,这种“递归下降”的表达式分析思想,仍然万变不离其宗,奠定了各种编程语言的基石
但是,光有栈结构还是不行,比如这个情况
1+2∗function(x)
我们假设function是一个非常复杂的函数,它需要的内存和x有关,也就是说,除非我们知道了x是多少,我们是无法确切知道到底需要多少内存才能完成运算的,并且,我们的机器本身内存比较小,例如我们已经分配了
1,2,3,4,5,6 的内存,但是假如1,2,3已经用不到了,正常情况下来说,我们应该将1,2,3从仓库里移出去以释放仓库的空间,但我们发现,4,5,6还在1,2,3的顶上,如果按上面的栈结构思想,要移出1,2,3就要先去掉4,5,6,从性能上看,这显然绕了个大弯,是一种运算性能的浪费.
因此,我们需要一个"地主租地"的内存管理办法,首先它能够管理大量的内存,能够以很高的效率频繁处理随机的,非连续的内存的"出租""回收"过程,因此你可以看到在现在讨论堆结构,几乎都是伴随着内存管理机制进行讨论的,但详细讨论这部分的内容,就是一个说来话长的东西了
优秀的内存管理机制,光一本书未必写得完,它涉及到多种数据结构与思想的运用,面临碎片处理,空间划分,索引效率,拼接整合等多个问题,如果你有兴趣,这里有一个我实现的轻量级内存池管理机制可以做个简单的示例
可以看到.不管是堆还是栈,都是内存应用与管理的不同方式,目的也是为了解决不同的问题.
因此与其说堆和栈是内存的划分方式,我更愿意称其为不同的内存管理与利用方式,纠结其叫什么,出处在哪,需不需要像法律条文一样明确的定义,这个根本不重要。重要的是明白它们的出现能够解决什么问题就行了。
自己看来栈只是一种数据结构更加合适,当初就想不明白栈和new内存都不是内存有什么区别,现在从程序角度来说只是内存数据结构而已,方便使用而已
